이번 블로그에서는 결정트리모델의 단점인 과적합문제를 보완하고 머신러닝에서 분류문제를 풀때 가장 많이 사용되는 랜덤포레스트모델(Random Forest Model)에 대해서 알아보도록 하겠습니다~!
< 개념 >
랜덤포레스트 모델은 결정나무를 기본 모델로 사용하는 앙상블(Ensemble) 방법입니다.
다시 말해서 결정나무(Decision Tree)를 여러개 만들어서 그 결과들을 종합적으로 고려하여 결론을 도출하는 방법입니다.
예를 들어 집단지성을 통해서 결론을 도출할 때 한쪽에 치우치지 않은 더 좋은 결론을 도출해낼 수 있는 것과 비슷한 원리라고 생각하면 될 것 같습니다.
앙상블(Ensemble) 방법이란?
강력한 하나의 모델을 사용하는 대신 보다 약한 여러개의 모델을 조합하여 더 정확한 예측을 해주는 방법입니다.
대표적으로 렌덤포레스트, XGboost, Light Boost등이 있습니다.
< Bagging >
앙상블 방법을 사용할 때 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 여러가지 방법들이 있는데 랜덤포레스트 모델은 이 중에서 배깅(Bagging)을 이용하여 모델을 만들고 학습을 합니다.
배깅이 무엇이고 랜덤포레스트에서는 배깅을 어떻게 사용하는지 알아봅시다!
Bagging은 Bootstraping + Aggregating을 합친 말입니다.
두가지 개념이 합쳐져있으므로 하나하나씩 알아봅시다.
먼저 부트스트랩(Bootstraping)은 데이터를 셈플링 하는 방법을 말합니다.
부트스트랩핑은 데이터에서 샘플링을 할 때 복원추출을 한다는 점이 가장 큰 특징입니다.
그리고 학습데이터셋을 여러가지로 유니크하게 만들 수 있다는 점이 특징입니다.
아래 그림을 보시면 하나의 부트스트랩에 같은 데이터가 들어가기도 하고
복원추출을 하기 때문에 각각의 부트스트랩 샘플링이 모두 다르게 생성이 됩니다.
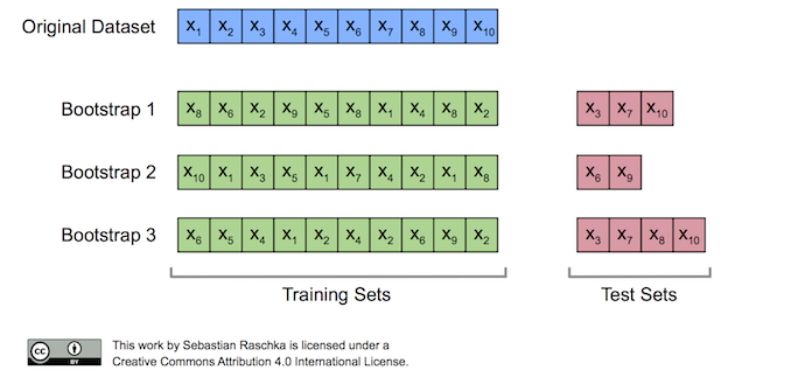
이렇게 부트스트랩한 데이터셋을 통해서 작은 결정나무(Decision Tree)들을 만듭니다.
이 나무들를 만들 때 주의할 점은 큰 나무 하나를 만드는것이 아니라 작은 나무 여러개를 만들어서 숲(Forest)을 이룬다는 점입니다.
문제를 풀 때도 한 명의 똑똑한 사람보다 100 명의 평범한 사람이 더 잘 푸는 원리라고 표현하기도 합니다.
다시 말해서 나무가 작다는 것은 노드가 적다는 의미이고 또 특성이 많지 않다는 뜻입니다.
즉, 모든 특성(Feature, column)들을 사용하는 것이 아니라 몇개의 특성들만 골라서 결정나무(Decision Tree)들을 만드는 것입니다.
이때 몇개의 특성을 선택하는 것이 좋을지 고민이 될 수 있는데 보통 전체 특성의 개수의 제곱근만큼 선택하는 것이 가장 성능이 좋다고 합니다. 그러니까 항상 좋은것은 아니고 경험적으로 이렇더라... 라는 것입니다. (일종의 rule of thumb)
이때 특성들을 무작위(Random)로 선택하기 때문에 Random이라는 표현이 사용된다고 생각하면 될 것 같습니다.
그리고 부트스트랩에서도 랜덤으로 데이터를 샘플링하기 때문에 랜덤한 트리를 만든다고 볼 수 있습니다.
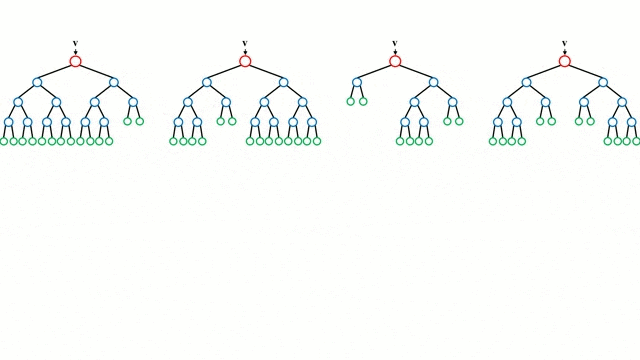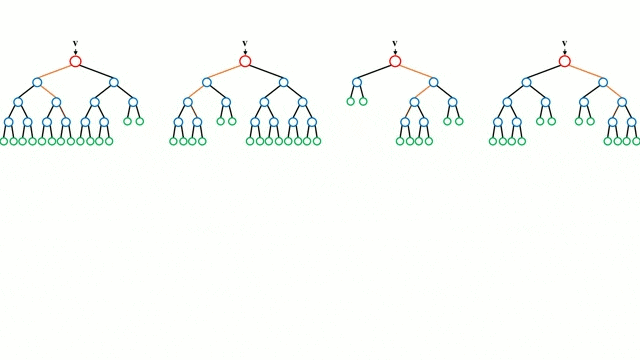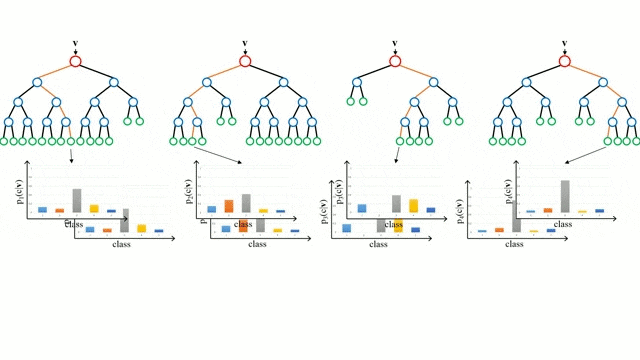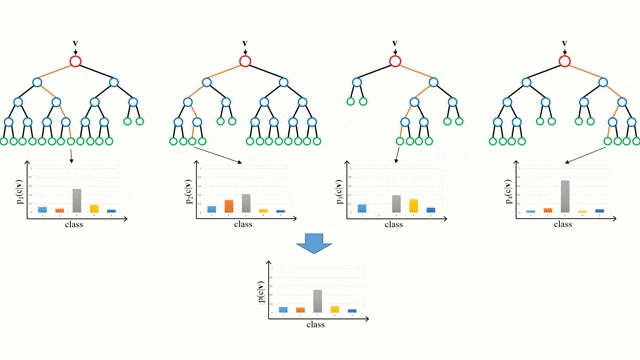
다음은 부트스트렙을 통해서 만들어놓은 여러가지 나무들을 합치는 과정(Aggregating)입니다.
- 회귀 문제일 경우 기본모델들의 결과들를 평균 내고
- 분류 문제일 경우 다수결로 투표를 해서 가장 많은 투표를 받은 것을 결과로 냅니다.
< OOB(Out-of-Bag)를 이용한 모델 평가 >
랜덤포레스트 모델을 평가할 때 사용할 수 있는 방법이 있습니다.
부트스트랩 샘플링을 할 때 중복을 허용하는 복원추출을 하기 때문에 훈련 데이터셋에 포함되지 않는 데이터가 생기게 됩니다. 이런 데이터들을 Out-of_bag이라고 하고 위의 그림에서는 test sets으로 나타나고 있습니다.
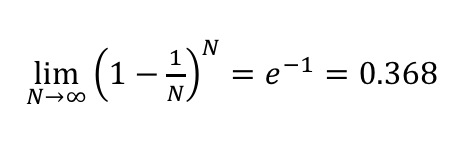
데이터의 크기가 클 때 36.8% 정도가 oob샘플이 되는 것으로 계산할 수 있고
이 데이터들을 모델에 직접 대입해서 모델을 검증(validate)해볼 수 있습니다.
(sklearn에서는 oob_score_ 라는 속성을 통해서 알 수 있습니다.)
이 oob_score를 보고 하이퍼파라미터를 튜닝하면서 모델일반화를 할 수 있습니다.
물론 처음부터 train,validation,test 데이터로 나눠서 평가하는 것과는 다른 방법이지만
데이터의 수가 적어서 따로 데이터를 떼어놓기 힘들 때 고려해 볼 수 있습니다.
< 특성중요도(variable importance) >
랜덤포레스트의 중요한 장점 중 하나인 특성 중요도에 대해서 알아보겠습니다.
랜덤포레스트에서는 학습 후에 특성들의 중요도 정보(Gini importance)를 기본으로 제공한다
랜덤포레스트는 노드들의 지니 불순도를 통해서 특성들의 중요도를 계산해줍니다.
노드가 중요할수록 불순도는 감소한다는 사실을 이용한 것입니다.
sklearn에서는 feature_importanace_라는 속성을 통해서 구할 수 있습니다.
< 랜덤 포레스트의 장점 >
랜덤포레스트의 장점은 위에서 살펴본 특징들을 정리한 것이라고 생각하면 될 것 같습니다.
1. 분류(classification), 회귀(Regression)문제에 모두 사용 가능함.
2. 결측치(Missing value)를 다루기 쉽다.
3. 대용량데이터 처리가 쉽다.
4. 과적합(Overfitting)문제를 해결해준다.
5. 특성중요도(Feature importance)를 구할 수 있다.
추가로 랜덤포레스트를 어떻게 만들고 학습이 되는지 단계별로 보고싶은 분들은 아래의 영상을 통해서 확인해볼 수 있습니다!
https://www.youtube.com/watch?v=J4Wdy0Wc_xQ
읽어주셔서 감사합니다!
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| 결정트리모델(Decision Tree Model) (0) | 2021.12.16 |
|---|