이번 블로그에서는 차원축소(dimension reduction)에 대해서 알아보도록 하겠습니다.
(목차)
1. 차원축소는 왜 해야하는가? (필요성) >> 차원의 저주(curse of dimension)
2. 차원축소의 종류
2.1 - 차원선택(feature selection)
2.2 - 차원추출(feature extraction) - PCA
1. 차원축소는 왜 해야하는가? (필요성) >> 차원의 저주(curse of dimension)
차원축소를 해야하는 가장 큰 이유는 차원의 저주(curse of dimension) 때문입니다.
차원의 저주란 데이터 학습을 위한 차원(=특성,변수,피쳐)이 증가하면서 학습데이터의 수 보다 차원의 수가 많아지게 되어 모델의 성능이 떨어지는 현상을 말합니다.
즉, 데이터보다 차원의 수가 더 많을 때 발생하는 현상입니다.
예를 들면 데이터의 수는 500개인데 차원이 1000개인 상황을 차원의 저주라고 말할 수 있습니다.
그리고 이런 상황에서 모델의 복잡도는 증가하지만 오히려 성능은 떨어지게 됩니다.
이유는 아래의 그림을 통해서 이해할 수 있습니다.
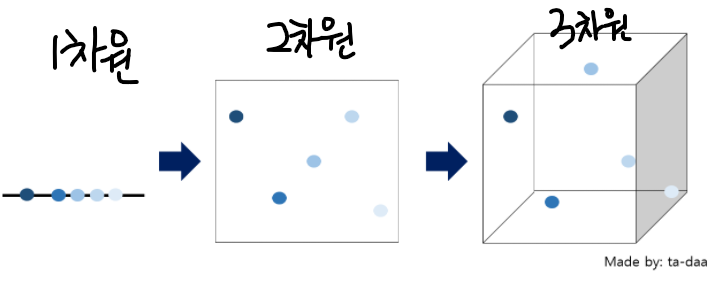
변수가 1개인 1차원에서는 하나의 '선'에서 데이터들이 비교적 붙어있는 것을 확인할 수 있습니다.
변수가 2개인 2차원 평면에서는 데이터들이 '선'으로 표현될 때 보다는 더 벌어져 있습니다.
마지막으로 3차원 공간에서는 데이터들 사이의 거리(점들 사이의 거리)가 더 멀어져 있는것을 확인할 수 있습니다.
이렇게 데이터간에 빈 공간이 생기는것을 데이터 성김현상(sparcity)이라고도 부르고
선형대수로 표현하자면 대부분이 0으로 가득차있는 벡터가 있는 분산행렬(sparse matrix)이라고 이해하면 됩니다.
그렇다면 이러한 공간들이 문제가 되는 이유는 무엇일까요?
컴퓨터는 모든 데이터를 숫자로 인식을 하게 되는데 빈공간이 많아졌다는 것은 0으로 채워진 공간이 많다는 것을 의미합니다. 즉 의미있는 정보가 상대적으로 적어진다고 볼 수 있습니다. 모델은 굉장히 복잡하지만 쓸만한 정보가 더 적어진다는 의미입니다.
이런 문제는 KNN(K-Nearest Neighborhood) 알고리즘을 사용할 때 가장 큰 문제점을 드러냅니다.
KNN알고리즘은 점들간의 거리를 계산해서 가까운 값들을 묶어 라벨링을 해주는 비지도학습 알고리즘인데 위의 그림처럼 빈공간이 많이 생기게 되면 점들간의 거리는 더욱더 멀어지게 되고 정확한 라벨링을 할 수 없는 문제가 발생하게 됩니다.
또한 차원의 수가 많아질경우 개별 특성(피쳐)들간의 상관관계가 높아질 가능성도 커집니다. 피쳐들간의 상관관계가 높아지게 되면 다중공선성문제가 발생할 수 있고 따라서 모델의 성능이 떨어지게 됩니다.
이러한 차원의 저주 문제를 해결하기 위해서 차원축소를 해야 합니다.
2. 차원축소의 종류
차원 축소는 말 그대로 차원을 줄여주는 알고리즘을 말합니다.
차원 축소를 할수 있는 방법으로는 크게 2가지가 있습니다. - 차원선택(selection) , 차원추출(extraction)
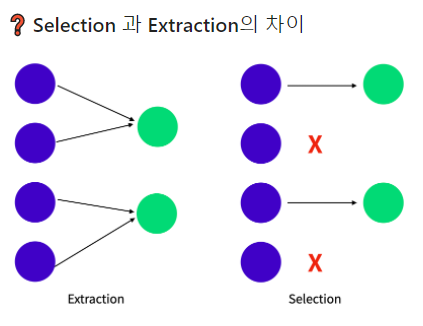
| 차원 선택 - selection | 차원 추출 - extraction | |
| 장점 | 선택된 feature 해석이 쉽다. | feature들 간의 연관성이 고려됨, feature의 수를 많이 줄일 수 있다. |
| 단점 | feature들간의 연관성은 고려되지 않는다. | 해석이 어렵다. |
| 예시 | SelectKBest, Variance Threshold, RFE... | PCA, LSA, LDA, SVD |
2.1 차원선택(feature selection)
차원선택은 하나의 기준을 정해서 특정 피쳐를 제거하여 타겟값을 예측하는데 가장 도움이 되는 피쳐만 남기는것을 말합니다.
- 분산을 기준으로 선택하기(Variance Threshold Feature Selection)
- input variable만을 가지고 선택함. 따라서 비지도학습에 많이 사용됩니다. - 일변량분석 점수를 기준으로 선택하기(univariate feature selection with SelectKBest)
-chi2, Pearson-correlation등을 이용해서 SelectKBest를 이용하면 구해낼 수 있다. - 모델의 계수와 특성중요도를 기준으로 선택하기(Recursive Feature Elimination(RFE))
-머신러닝 모델의 coef_, feature_importance_ attribute를 이용해서 가장 중요도가 낮은 특성을 반복적으로 제거하는 방법으로 특성을 선택한다. - 교차검증으로 나온 점수를 기준으로 선택하기(Feature Selection Sequential Feature Selection(SFS))
- 교차검증시 가장 점수가 높은 특성을 하나씩 추가하면서 원하는 특성의 개수만큼 선택하는 방법입니다.
2.2 차원추출(feature extraction)
차원추출은 피처를 선택하는 것이 아닌 더 작은 피쳐들로 맵핑하는 방법이다.예를 들면 100개의 피쳐를 모두 녹여서 50개의 피쳐로 만드는 것이다.
- 주성분분석 PCA
- 제일 대표적으로 많이 사용되는 기법으로
- 단순히 피쳐들을 제거하는 방법이 아닌 여러 피쳐들이 갖는 정보를 하나로 압축하는 방법입니다.
- 설명력이 높은 순서부터 낮은 순서로 정렬이 가능해지므로 노이즈제거에도 이용되는 개념이다. - LDA
- LSA
- SVD
참고 사이트
https://scikit-learn.org/stable/modules/feature_selection.html
https://towardsdatascience.com/5-feature-selection-method-from-scikit-learn-you-should-know-ed4d116e4172 https://towardsdatascience.com/5-must-know-dimensionality-reduction-techniques-via-prince-e6ffb27e55d1
https://blog.naver.com/PostView.naver?blogId=paragonyun&logNo=222465847517&from=search&redirect=Log&widgetTypeCall=true&directAccess=false