코드스테이츠 AI 부트캠프 3기 section2 프로젝트 내용을 정리한 것입니다.
1. 개요
전세계 맥주데이터를 분석하여 소비자들이 어떤 맥주를 선호하는지 머신러닝 기법을 통해서 분석하고 결론을 도출하는 프로젝트 입니다.
2. 프로젝트의 목표
알코올 함유량에 따라서 소비자들의 맥주 선호도가 달라지는지 확인해보려고 한다.
가설은 다음과 같이 설정해보았다.
가설 : 알코올의 함유량에 따라 맥주에 대한 소비자들의 평가가 다를것이다.
3. 데이터
총 5500개 정도의 데이터와 21개의 피처를 가지고 있는 맥주데이터 입니다.
(데이터 출처 : https://www.kaggle.com/stephenpolozoff/top-beer-information?select=beer_data_set.csv)
앞에서부터 10개의 피처는 맥주의 이름(Name)이나 양조장(Brewery), 제조방식(Style) 등에 관한 내용이고
그 뒤로 이어지는 11개의 피처는 이 맥주를 마신 사람의 리뷰에서 나온 단어를 센 것이다.(word counts)
당연히 사람들이 맥주를 마셔보고 직접 느낀 맛에 대해서 더 많이 언급할 것이라는 가정이다.
분류(Classification) vs 회귀(Regression)
target = recommend(추천)
평점이 높은 맥주는 충분히 대부분의 소비자들의 입맛을 만족시키고 있다는 의미이므로
평점 70% 이상인 맥주는 개발 회사들에게 추천(recommend)할 만 하다고 판단하였습니다.
그래서 [추천하는 맥주/ 추천대상이 아닌 맥주] 분류 문제로 설정하였습니다.

4. EDA, 전처리, 특성공학
EDA
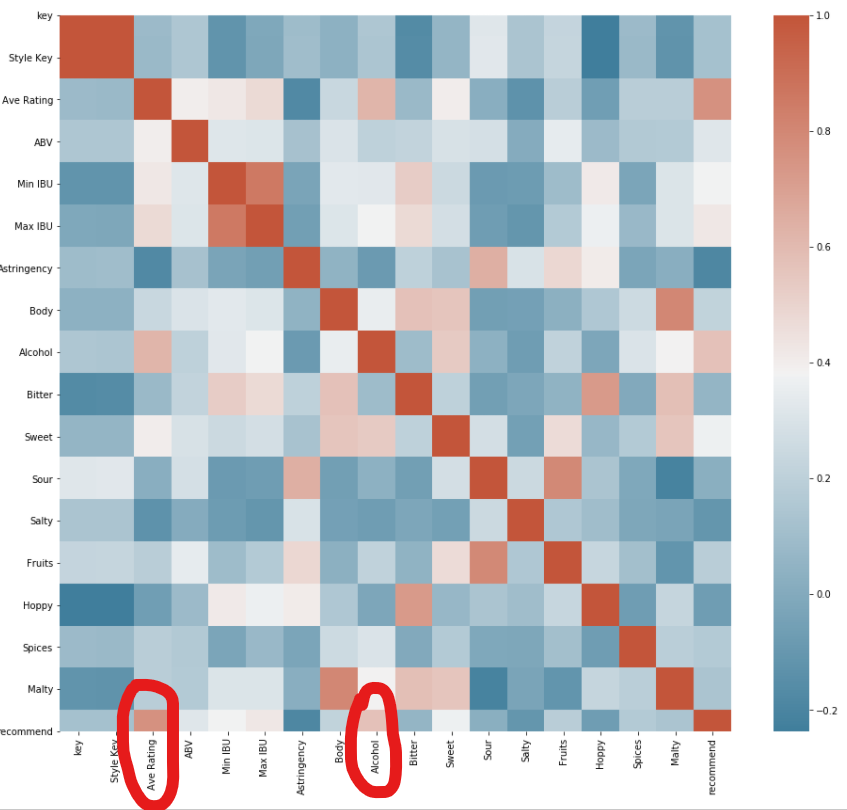
각 피쳐별로 산점도도 그려보고 또 히트맵을 그려서 상관관계를 알아보고자 하였으나 특별한 관계를 알아내지는 못하였다.
밑에서 얘기하겠지만 한가지 알아낼 수 있었던 사실은
타겟값인 recommend와 가장 큰 상관관계를 보이는 칼럼은 Ave Rating을 제외하고 Alcohol인 것을 확인할 수 있습니다.
Ave Rating을 통해서 타겟값인 recommend타겟값을 만들었으므로 Data leakage 방지를 위해서 나중에 전처리할때 제거하도록 할 것입니다.
결측치와 중복값 확인하고 처리를 해주었습니다.
전처리
1. 이상치 확인
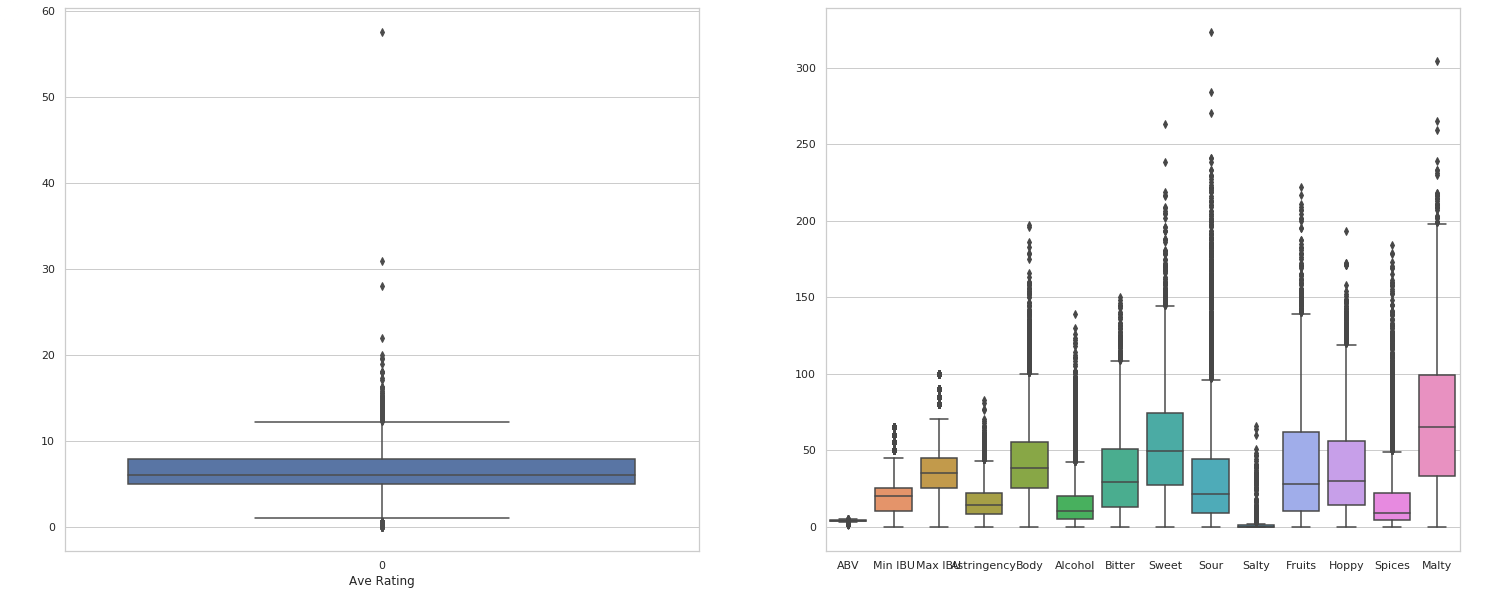
이상치를 확인하기 위해서 box plot을 그려보았다.
대부분의 피쳐에서 이상치가 나타나는 것을 확인하였고 이런 이상치들을 다 제거하게 될 경우 원래의 데이터의 속성을 잃어버릴 수도 있다고 생각하여서 평점(Ave Rating) 특성만 이상치 제거를 해주었습니다.
2. 데이터 분포 확인
아래의 그래프들은 각 피쳐별로 히스토그램을 찍어본 것이다.
대부분의 피쳐에서 한쪽으로 쏠려있는 모습을 볼 수 있다. 이럴때 유용하게 사용할 수 있는 방법은 로그를 취해주는 것이다.
로그를 취해주면 정규성을 높여주고 따라서 분석을 할 때(회귀분석,,,) 더 정확한 값을 얻을 수 있다.
두번째 그래프를 보면 편차가 줄어들고 정규분포 모양으로 그래프들이 변한 것을 확인할 수 있다.(Alcohol, Sour같은 피쳐들...)


특성공학(Feature engineering)
대형 양조장들은 더 맥주를 잘 만들지 않을까 싶어서 대형양조장(Big Brewery)라는 새로운 피쳐를 만들었습니다.
또한 카디널리티를 가지는 피쳐와 target정보가 포함되어 있는 Ave Rating피쳐는 데이터누출(Data Leakage) 방지를 위해 제거하였습니다.

5. 기준모델과 사용할 평가 지표
기준모델 - 타겟의 최빈값
분류 문제이므로 타겟의 최빈값을 기준모델로 두고 모델링을 할 계획입니다.
기준모델이란 예측 모델을 구체적으로 만들기 전에 가장 간단하면서도 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델을 기준모델 이라고 합니다
적어도 기준모델보다는 좋은 성능을 가진 모델을 만들어야 의미있는 분석과 머신러닝 모델이 만들어졌다는 뜻입니다.

평가지표 - Accuracy,Precision,Recall,F1-score
분류문제에서 쓰이는 평가지표로는 Accuracy, Precision, Recall, F1-score 등 여러가지 지표들이 있습니다.
지금 이 프로젝트는 새로운 맥주개발회사에 맥주를 추천하는 문제입니다.
만약 우리가 만든 모델이 추천하지 말아야 할 맥주를 추천하게 된다면 개발회사에 막대한 손실을 유발할 수 있습니다.
따라서 이러한 문제가 생기지 않는 방향으로 모델링을 해야 합니다.
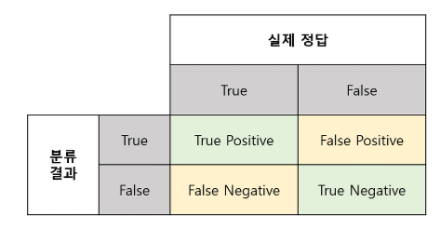
즉, FN(False Positive)가 가장 적게 나타나도록 모델링 방향을 잡아야 합니다.
따라서 앞으로 여러가지 모델을 만들어보고 성능을 비교할 때 다양한 평가지표들을 모두 고려하여 비교하겠지만 제일 중요하게 비중을 두어야 하는 평가지표는 정밀도(Precision)입니다. .

6. 모델링(Modeling)
이번 분석을 위해서 총 세가지 모델을 사용해보았습니다.
- 로지스틱 회귀(Logistic Regression)
- 랜덤포레스트 서치 (Randomforest classifier Search)
- XGboost
모델에 대한 코드는 아래 링크에 첨부해놓았으니 궁금하신 분들은 들어가셔서 보시면 되겠습니다!
7. 성능비교 및 모델 선택
- 로지스틱 모델
훈련데이터 성능: 0.8538177689469202
검증데이터 성능: 0.8637911464245176
테스트데이터 성능: 0.8430127041742287
f1-score : 0.7111853088480803
precision recall f1-score support
0 0.87 0.92 0.89 780
1 0.77 0.66 0.71 322
accuracy 0.84 1102
macro avg 0.82 0.79 0.80 1102
weighted avg 0.84 0.84 0.84 1102

- RandomforestCV 모델
훈련데이터 성능: 0.9662219699120068
검증데이터 성능: 0.9023836549375709
테스트데이터 성능: 0.8693284936479129
f1-score : 0.7517241379310343
precision recall f1-score support
0 0.88 0.95 0.91 780
1 0.84 0.68 0.75 322
accuracy 0.87 1102
macro avg 0.86 0.81 0.83 1102
weighted avg 0.87 0.87 0.86 1102

- XGboost모델
훈련데이터 성능: 0.9897814362759012
검증데이터 성능: 0.8933030646992054
테스트데이터 성능: 0.8693284936479129
f1-score : 0.7770897832817337
precision recall f1-score support
0 0.91 0.91 0.91 780
1 0.77 0.78 0.78 322
accuracy 0.87 1102
macro avg 0.84 0.84 0.84 1102
weighted avg 0.87 0.87 0.87 1102


🔥🔥🔥 RandomForestCV모델 선택 🔥🔥🔥
검증정확도와 테스트정확도가 세개의 모델중에서 가장 높으며
맥주를 추천하는 이번 프로젝트의 문제에서 가장 중요한 정밀도(Precision) 점수가 가장 높다.
참고로 제일 피해야 하는 케이스인 ,FP(추천했지만 실제로는 추천대상이 아닌, 큰 손실을 유발할 수 있다)가 가장 적으므로
RandomForest모델을 선택합니다.
8. 유용성 및 한계
이 프로젝트에서 최종적으로 선택한 모델은 RandomForest모델입니다.
그리고 하이퍼 파라미터의 최적값을 찾기위해서 RandomizedCV를 사용하여 하이퍼 파라미터를 튜닝한 RandomForest모델을 사용하였습니다.
유용성
- 이 모델을 통해서 어떤 특성들이 소비자의 맥주 만족도에 큰 영향을 주는지를 알 수 있습니다.
한계
- 맛 특성들이 객관적인 성분검사를 통해서 나온 값들이 아니라 맥주를 시음한 뒤 맛에 대한 평가에서 나온 단어들의 수를 나타내는 것이므로 상당히 주관적일 수 밖에 없습니다.
- 또한 알코올이나 다른 맛의 특성들이 소비자의 만족도에 영향을 끼친다는 것을 확인했지만 새로운 맥주를 개발하기위해서 어떤 조합의 맛과 알코올 농도를 가진 맥주가 좋다라는 정확한 예측은 불가능하다.
🏆 결론
우리가 처음에 세웠던 가설을 다시한번 생각해보자. 결국 이 가설이 맞는지 틀린지를 검증해보기 위해서 이러한 분석을 한 것이다.
🔥 가설 : 알코올의 함유량에 따라 맥주에 대한 소비자들의 평가가 다를것이다🔥
이 가설이 틀리지 않았음을 확인 할 수 있습니다.

읽어주셔서 감사합니다.
전체 코드 코렙링크
(https://colab.research.google.com/github/aytekin827/AIB_sec2_project/blob/main/sec2_project_%5B%EC%A0%95%EB%AF%BC%EC%9E%AC%5D.ipynb#scrollTo=82HjGtpMhTvm)
'데이터 분석 > 프로젝트' 카테고리의 다른 글
| 도움이 되는 리뷰(helpful review) 분류기 with huggingface, torch (0) | 2023.01.31 |
|---|---|
| NSMC 영화리뷰 데이터 감성분석(Sentiment Analysis) - Word2Vec + LSTM (0) | 2023.01.17 |
| 비디오 게임 데이터를 이용하여 출시할 게임 설계하기 (0) | 2022.01.01 |