# 1543번: 문서 검색
doc = input()
word = input()
length = len(word)
flag = [0 for i in range(len(doc))]
cnt = 0
for i in range(len(doc)):
if flag[i] == 1:
continue
if word == doc[i:i+length]:
cnt += 1
for idx in range(i,i+length):
flag[idx] = 1
print(cnt)중복 값을 어떻게 처리하면 좋을지 생각하다가
리스트를 사용해서 한번 본 문자의 인덱스에 표시를 해두는 것으로 구현해보았다.
다행히 한 번에 통과가 되었다.
그런데 이번 문제를 풀면서 새롭게 알게 된 부분은
리스트 슬라이스 작업에는 index out of range에러가 발생하지 않는다는 사실이다.
처음 문제를 풀 때에는 리스트부분에서 인덱스 에러(index out of range)가 날 수도 있을 것이라 생각해서
doc[i:i+length] 이 부분을 try, except 구문을 사용해서 풀어보았는데
결과적으로는 필요 없는 작업이었다.
리스트 슬라이싱 할 때에는 index out of range에러가 나지 않는 듯하다.
아래 스크린숏 결과를 보면 리스트의 값을 인덱스로 접근할 때에는 인덱스 에러(IndexError)가 발생하지만
리스트 슬라이스에서는 아무리 큰 값을 주어도 인덱스 에러가 나지 않는다.
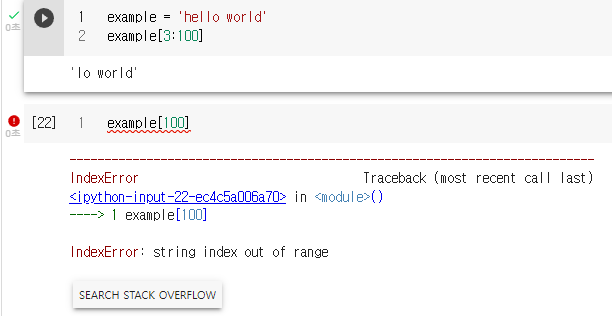
이유가 궁금하여 구글링을 해보니
슬라이싱을 할 경우에는 return 값을 리스트 형식으로 주고
따라서 index범위를 넘어서는 부분을 슬라이싱을 한다고 해도 빈 리스트 []를 return 할 뿐 에러는 내지 않는다.
하지만 인덱싱(indexing)을 할 경우엔 리스트의 범위를 벗어나게 되면 에러를 준다고 한다.
이유는 파이썬 제작자들이 그렇게 제작을 했기 때문이라고...
더 자세하게 알고 싶으신 분들은 아래 블로그를 한번 읽어보시면 좋을 듯하다.
https://blog.finxter.com/daily-python-puzzle-overshoot-index-slicing/
Why Slicing With Index Out Of Range Works In Python? – Finxter
Python slicing means to access a subsequence of a sequence type using the notation [start:end]. A little-known feature of slicing is that it has robust end indices. Slicing is robust even if the end index is greater than the maximal sequence index. The sli
blog.finxter.com
요약하자면 범위를 벗어나는 indexing에서도 None값을 줄 수도 있지만 문제는 실제로 리스트 안에 None값이 저장되어 그 값을 indexing 하는 경우와 차이가 없기 때문에 에러 값을 주는 것이라고 한다.
이유를 들어보니 맞는 말이다.
당연히 그렇겠지만 실제로도 그렇다...

'알고리즘 문제풀이 > Greedy' 카테고리의 다른 글
| 백준 2847번: 게임을 만든 동준이 - 파이썬(greedy) (0) | 2022.04.19 |
|---|---|
| 백준 1449번: 수리공 항승 - 파이썬(greedy) (0) | 2022.04.17 |
| 백준 2437 파이썬(그리디) (0) | 2022.02.10 |
| 백준 1080 파이썬(그리디) (0) | 2022.02.09 |
| 백준 1049 파이썬(그리디) (0) | 2022.02.08 |